



Starlink Global Outage: Single-Point Software Failures
Thousands of satellites can still share one weak point: the software services that coordinate the entire constellation.
By: Aaron Gilmore — Intergalactic SEM Consultant (humans only so far)
Human Lead, Automation-Enhanced. SEM-Artificium
QuickScan
Large distributed systems can still fail from a single control-plane dependency.
Resilience requires mapping hidden dependencies (especially software coordination services).
For mission/field operations, you need a practiced PACE plan—not a slide deck.
Build “graceful degradation” expectations: what still works when coordination fails?
For Who Primary audience: DoD/Federal Supply Chain Best for roles: Continuity/Resilience leads, Network/Comms planners, SOC/IR, Program management, Mission owners relying on satellite internet
What You’ll Get You will learn: How a software coordination failure can cause global service loss in a highly distributed system.
You will be able to do: Identify control-plane single points of failure and translate them into a practical PACE communications plan.
Time & Effort Read time: 6–8 minutes
Do time (optional): 45–90 minutes
Difficulty: Intermediate
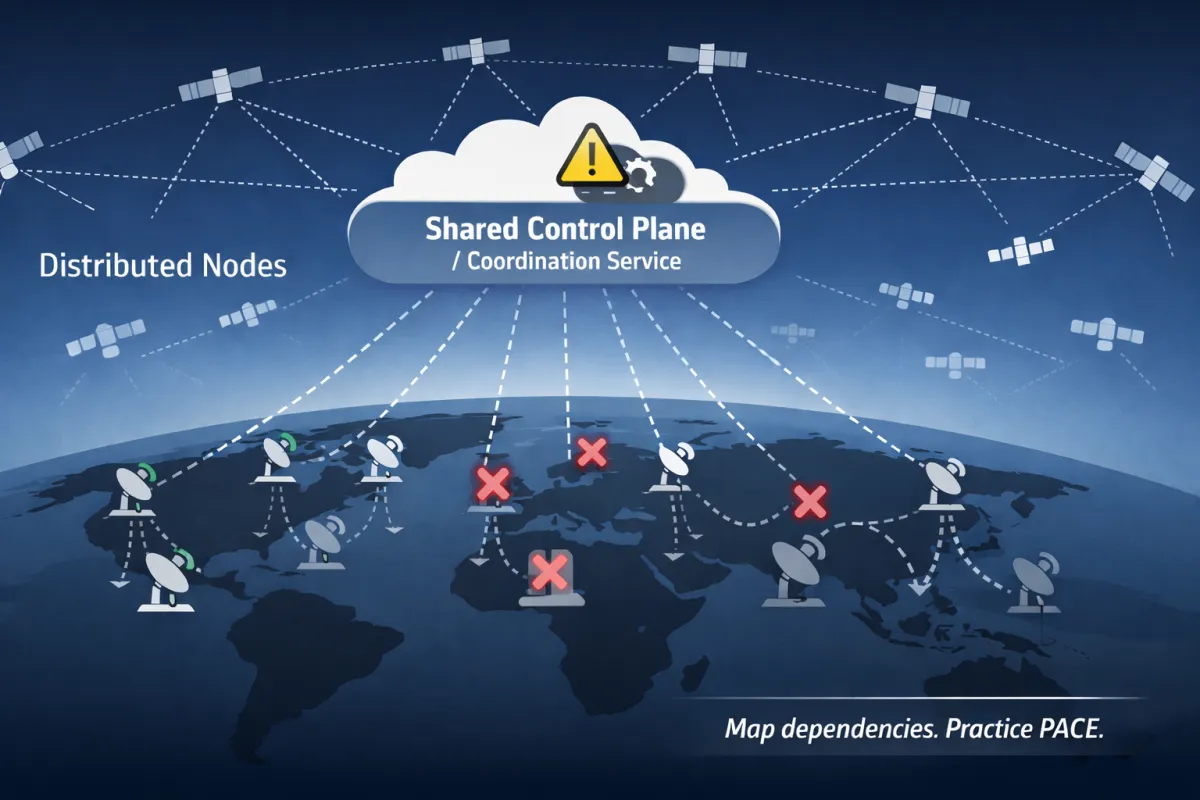
A global system can still share one weak point: the control plane.
Executive Snapshot
What happened: On July 24, 2025, SpaceX’s Starlink experienced a rare, global outage lasting about 2.5 hours. Starlink leadership attributed the disruption to a failure of “key internal software services” operating the core network.
Why it matters: This wasn’t a regional fiber cut or a single ground station issue. It was an outage at the control level—the kind that can drop service globally and instantly for any organization that depends on Starlink for mission connectivity, remote operations, or emergency communications.
Key lesson: A highly distributed system can still have a single-point software failure—so resilience depends on dependency mapping, minimum-service operating modes, and outage communications discipline.
What to do now:
Dependency-map Starlink (and any “must-work” comms) like a critical utility: where it enables operations, safety, and command-and-control.
Design a Minimum-Service Operating Mode (MSOM): what you will still do safely when Starlink is down for 3 hours, 24 hours, or 72 hours.
Pre-script outage communications (internal + external): who speaks, what you say, and how often you update when the status is uncertain.
Field Notes Opening
Starlink feels like a magic trick: point a dish at the sky and the internet appears. That’s why outages hit harder than we expect. The dependency is invisible until it’s gone. And when it goes—globally—the failure isn’t at the edge (the dish). It’s in the brain: the software services coordinating a moving constellation, routing traffic, and deciding which satellites talk to which users.
This Field Note is about how to treat “satellite internet” as what it actually is for many organizations: a mission-critical control plane dependency.
What We Know (Verified Facts)
Confirmed facts:
The outage occurred on July 24, 2025 and lasted about 2.5 hours, affecting users globally.
Reuters reported Starlink was restored and engineers were investigating the root cause; Starlink’s leadership said the outage was due to the failure of “key internal software services” that operate the core network.
Downdetector recorded a spike in complaints (tens of thousands; Reuters cited as high as ~61,000 reports).
Reuters reported operational impacts in Ukraine, where a commander of Ukraine’s drone forces said service was down across the entire front and affected combat operations.
Independent network monitoring analysis (ThousandEyes) described the outage pattern as system-wide and consistent with a failure in Starlink’s centralized, software-defined control plane.
Key actor statements:
Starlink Engineering leadership and Elon Musk publicly apologized and stated the root cause would be found and addressed.
What We Don’t Know Yet (Unverified / Evolving)
Open questions / uncertain details:
Root cause specifics: Which “key internal software services” failed and why.
Trigger: Reuters noted speculation about a botched software update versus a cyberattack (not confirmed).
Control-plane architecture details: What redundancy exists, where it failed, and what changes were implemented after the incident.
Second-order impacts: Full accounting of impacts across government/military users and critical services is not publicly detailed.
Assumptions used in this article
We assume many organizations use Starlink as a primary or failover path for remote sites, field operations, maritime/aviation connectivity, and crisis communications.
Timeline
July 24, 2025 (~19:13 UTC): Global Starlink outage begins (reports spike across regions).
During the outage: User terminals cycle reconnection attempts; patterns suggest a system-wide control-plane issue (monitoring analysis).
~2.5 hours later: Service mostly restored; Starlink reports the network issue resolved.
July 25, 2025: Reuters reports SpaceX engineers investigating root cause; leadership states outage tied to failure of key internal software services.
Why This Matters (So What?)
For DoD/Federal supply chain leaders
A global comms dependency is a supply chain dependency. If programs, primes, subs, depots, logistics nodes, or deployed teams rely on a single provider for field connectivity, your operational tempo inherits that provider’s failure modes.
A 2.5-hour outage is long enough to break:
omission reporting windows,
oUAV/drone tasking loops,
oconvoy coordination,
ofield medical coordination,
oemergency alerting,
oremote maintenance support.
For critical infrastructure and private-sector ops
Many remote sites now run on cloud tools, SaaS operations, and real-time comms. If your site has “internet-as-oxygen,” then “internet outage” becomes an operations safety problem—not an IT inconvenience.
The subtle lesson
Distributed infrastructure can still centralize risk in the control plane. ThousandEyes described Starlink as centrally coordinated via a software-defined control plane; when a control plane fails, a global single point of failure can emerge.
SME Doctrine Translation
Doctrine focus:
Dependency mapping (operational dependencies, not just asset lists)
Single points of failure (especially control-plane dependencies)
Minimum-Service Operating Mode (MSOM) planning
Outage communications as a capability (cadence + credibility)
Plain-English explanation
If you depend on a system that feels “everywhere,” you can be tempted to treat it as “always on.” Starlink’s outage is a reminder that availability is not guaranteed—even at global scale—and that software failures can propagate instantly. Your resilience posture should assume: a key service will fail at the worst time, and your job is to keep the mission running safely anyway.
That’s why high-maturity organizations do three things:
Map the dependency (“What breaks if this goes away?”)
Define the minimum service (“What must we still do?”)
Practice communications (“How do we lead people through uncertainty?”)
Controls / practices that apply:
Dependency map by mission thread: which tasks rely on Starlink (command, safety, dispatch, remote access, telemetry, incident reporting).
A P/A/C/E comms design (Primary/Alternate/Contingency/Emergency): ensure at least one non-Starlink path exists for critical messages.
MSOM runbooks: “how we operate for 3/24/72 hours with degraded comms,” including what is paused, what continues, and what manual procedures are used.
Outage comms discipline: one owner for updates, consistent cadence, and a single source of truth (status page, internal channel, radio net, etc.).
Contracting and governance: SLAs, outage notification expectations, and escalation paths for comms providers.

Figure 1 - “Control Plane vs Edge: How a Global Outage Happens” [Aaron Gilmore] {Diagram showing endpoints connecting to satellites and depending on a centralized control plane; a failure at the control plane causes cascading loss of connectivity across regions.
Lessons Learned (What this incident teaches)
Lesson 1: “Global” is not the same as “redundant.” A large footprint can still rely on a small set of software services to coordinate the whole system.
Lesson 2: Control-plane failures produce edge chaos. When coordination fails, endpoints can behave like they’re broken—even if the hardware is fine.
Lesson 3: Outage communications are part of continuity—not PR. If you can’t communicate during an outage, you can’t coordinate response, safety, or recovery.
Lesson 4: Minimum service needs owners and triggers. If your plan is “we’ll figure it out,” you don’t have a plan.
Role-Based Implications (Who should do what)
Executive leadership / Program leadership:
Require a list of Top 10 availability dependencies and their fallback modes.
Approve an MSOM policy: what the organization will stop, slow, or continue when comms are degraded.
Communications / Public Affairs / Stakeholder Comms:
Build an outage message package: “what we know, what we’re doing, when next update arrives.”
Pre-stage channels that do not rely on the primary internet path (phone trees, SMS, radios, alternate status endpoints).
Cyber / IT / Network Engineering
Identify failure modes tied to centralized services (identity, DNS, control planes, remote access, VPN concentrators).
Test failover paths and routing policies under stress.
Continuity / COOP / Emergency Management
Turn “comms outage” into a drill: run the business for 2 hours with primary comms down.
Ensure essential functions have non-internet alternatives (manual checklists, local control, paper forms).
Contracting / Supply Chain
Treat comms providers as tier-0 suppliers for mission threads.
Require clear outage notification, escalation, and restoration expectations.
What To Do Now (Field Application)
Immediate Actions (24–72 hours)
Action 1: Build a dependency map (fast version).
List every site/team using Starlink.
For each, list the top 3 tasks that fail if Starlink goes down.
Action 2: Define an MSOM for each site/team.
“If Starlink is down for 3 hours, we will…”
“If Starlink is down for 24 hours, we will…”
“If Starlink is down for 72 hours, we will…”
Action 3: Create an outage comms cadence.
Who posts updates.
Where the authoritative updates live.
Update rhythm: every 15–30 minutes until stable, then hourly.
Evidence to capture
Dependency map, MSOM runbooks, comms templates, drill results, and after-action items.
“Done” criteria
You can run at least one mission thread safely for 2 hours without Starlink and document what worked and what broke.

Figure 2 - “PACE Comms Plan for a Field Team (Primary → Alternate → Contingency → Emergency)” [Aaron Gilmore] {Stacked ladder showing Primary, Alternate, Contingency, and Emergency communication options for a field team, with a note to avoid shared dependencies.}
Note from the Author
If this outage made you uncomfortable, that’s useful data. It’s telling you where your organization silently upgraded Starlink from “nice-to-have” to “can’t-function-without.” Name that dependency, design for it, and practice it. If you don't use Starlink and think your safe from telecom failure and vulnerability .. no your not 🤣. Right now the CCP is still actively harvesting all our telecommunications in the USA, due to "providers" in the telecommunications industry being a victim of "Operation Salt Typhoon". It started as an outage, until TMobile reported to president Biden as the first telecom company to do so as a national security threat warning, and then reported they shut down their servers to cleanse the cyber threat. A majority of US telecom firms, still to this day have the CCP embedded into their systems/servers directly as they have not properly addressed these cyber threats, because "legally" they don't have to and/or the FCC has not been enforcing these laws/regulations so far (cybersecurity is honestly OPTIONAL in US law a majority of the time unfortunately). In the US army, I was a 25U, a MacGyver of battlefield communications so this is in fact "my jam". I would highly suggest you read about "Salt Typhoon" before I eventually make an article about it. Depending on who is your provider, the CCP is !!STILL!! actively tapped into your line (voice and text) and your telecom provider be letting them still do it unfortunately.
Reference List
Reuters. (2025, July 25). SpaceX probes for cause of Starlink’s global satellite network outage. Reuters. https://www.reuters.com/technology/spacex-probes-cause-starlinks-global-satellite-network-outage-2025-07-25/
Reuters. (2025, July 24). Musk’s Starlink says it is experiencing major network outage. Reuters. https://www.reuters.com/technology/musks-starlink-says-it-is-experiencing-major-network-outage-2025-07-24/
ThousandEyes. (2025, July 24). Starlink Outage Analysis: July 24, 2025. ThousandEyes. https://www.thousandeyes.com/blog/starlink-outage-analysis-july-24-2025
National Institute of Standards and Technology. (2010, May). Contingency planning guide for federal information systems (NIST SP 800-34 Rev. 1). NIST. https://csrc.nist.gov/pubs/sp/800/34/r1/upd1/final
National Institute of Standards and Technology. (2020). Security and privacy controls for information systems and organizations (NIST SP 800-53 Rev. 5). NIST. https://doi.org/10.6028/NIST.SP.800-53r5



